各AIモデルによる第119回医師国家試験の解答精度の評価
2026年2月8日追記:第120回医師国家試験でも同様の検証を行いました.こちらの記事をご覧ください.
本記事の更新情報
・3月15日15時30分:3/14に発表された厚生労働省の解答をもとに,情報を最終版に更新しました.また,考察部分を追記しました.・2月21日18時50分:本日18時時点の講師速報の解答速報と入力データに基づき,一部情報を更新しました.また,新たにDeepSeek R1の結果を追記しました.
・2月10日13時20分:本日13時時点の講師速報のデータに基づき,一部情報を更新しました.
・2月9日22時40分:全問題の回答結果を踏まえ,解答精度の検証内容を更新しました.
・2月9日16時:A~Cブロックの回答結果のまとめを追加しました.D~Fブロックまで含めた検証は後日公開します.
・2月8日16時:記事をアップしました.解答精度の検証は後日更新予定です.
本記事の監修者
|
|
長嶋大地
大分大学医学部出身. |
序文
本ページでは,第119回医師国家試験を代表的な各AIサービスに解かせ,結果について検証・考察していく.検証対象は2025年2月時点でのAIモデルである点に留意されたい.
医師国家試験の概要
今回分析対象とするのは,2025年2月8日,9日に実施された第119回医師国家試験である.2日間計400問の試験であり,マークシート形式が採用されている.A~Fブロックの6ブロック構成で,このうちB,Eブロックが必修問題,その他が一般臨床問題である.
合格基準など詳細については,こちらの記事を参照してほしい.
検証対象のAIモデル
今回,第119回医師国家試験を解かせるAIは以下の6モデルである(なお,各社より提供されているAPIを用いて検証を行う)。
| モデル名 | 概要 |
|---|---|
| GPT-4o |
提供元 :Open AI 入力形態:テキスト・画像・音声 API名 :gpt-4o-2024-11-20 ・Open AI社が2018年から発表したLLM(大規模言語モデル)であるGPT系列の第4バージョン,GPT-4をマルチモーダル化したモデル.テキストの入出力のみならず,画像,音声を処理することができる. |
| OpenAI o1 |
提供元 :Open AI 入力形態:テキスト・画像・音声 API名 :o1 ・Open AI社が世界に初めて出したAIの推論モデル.LLMに対して強化学習の手法を用いることで,AIのユーザーへの出力の前に,推論時計算リソースを使って与えられた問題を解決するための推論トークン文章を事前に出力し,出力精度を向上させる技術を使用している. |
| OpenAI o3-mini |
提供元 :Open AI 入力形態:テキスト API名 :o3-mini ・Open AI o1の後継モデル. リーゾニングモデル(考えるAI)で考える力をlow, mid, highの3種類から選ぶことができる. 今回はo1に匹敵されるとされるo3-mini-highを選択. |
| Claude 3.5 Sonnet |
提供元 :Anthropic 入力形態:テキスト・画像・音声 API名 :claude-3-5-sonnet-20241022 ・Anthropic社が発表しているLLMの最新3.5におけるモデル.Haiku,Sonnet,Opusという順にモデルサイズと精度の違うAIを提供しており,画像とテキストのマルチモーダルに対応している. |
| DeepSeek-R1 |
提供元 :DeepSeek 入力形態:テキスト API名 :deepseek-reasoner ・DeepSeek社が発表しているLLM.前モデルであるDeepSeek-V3をベースに,強化学習によって推論能力を大幅に向上させている.他のLLMと異なりオープンウェイトであることが特徴. ・(2025/2/21追記)2/14時点で,DeepSeek-R1のAPIが極めて不安定であったため,Microsoft Azure上でDeepSeek-R1をセルフホスティングし,独自にAPIとして構築したものを用いて結果を出力した. |
| Gemini |
提供元 :Google 入力形態:テキスト・画像 API名 :gemini-2.0-flash ・Google社の開発するテキスト・画像・音声を処理できるマルチモーダルAIモデルの軽量版. |
プロンプト
今回の検証では,以下のプロンプト(指示文)を用いることでAIに医師国試を解かせた.
なお,119回医師国試の問題文については記事執筆時点では厚生労働省よりPDFが公開されていないため,受験生提供の問題冊子をもとに入力した.
あなたは医師国家試験の問題を解く専門家です。 与えられた問題に対して、最も適切な選択肢を選んでください。以下のルールに従って回答してください: 1. 問題文に「2つ選べ」などの指示がない限り、必ず1つだけ選択してください 2. 問題文で複数選択が指示されている場合のみ、複数の選択肢を選んでください 3. 複数選択の場合は、選択肢をアルファベット順に並べて出力してください(例:ac, ce)
回答は以下の形式で出力してください。 "answer": [選択した回答のアルファベット], "confidence": [0.0-1.0の確信度], "explanation": [回答の理由を簡潔に]
今回の検証したAIシステムの大半はマルチモーダル・AIモデルと呼ばれる,画像や音声といった複数のモダリティを処理することのできるシステムである.しかしながらテキストのみの単一モダリティのモデルでも高度な人工知能と評価されているモデルもあり,それぞれのAIによってテキスト,画像,音声の認識レベルには大きな差がある.
医師国家試験では,テキストのみで表せる問題と,医療画像や表組みを含んだ問題が混在している.国試の性質上,医療画像を含んだ問題であっても,その他の情報から解答を導ける問題も多いが,とはいえAIモデルが問題を解く際に画像を提供するか否かは解答精度に大きな影響を与えると予想される.そのため,問題が画像を含むか否かで正答率の検証を分けることする.
AIによる119回医師国家試験の回答
以下に,各AIモデルの回答を順次まとめていく.なお,検証にあたっては「解答」の他に「解答の確信度」「解答の根拠」も出力させているが,スペースの都合上ここでは割愛する.
Aブロックの回答まとめ
Bブロックの回答まとめ
Cブロックの回答まとめ
Dブロックの回答まとめ
Eブロックの回答まとめ
Fブロックの回答まとめ
AIによる回答の精度検証
AIによる回答の検証が進み次第,本項にて随時まとめていく.なお,厚生労働省より119回医師国家試験の解答が発表されるまでは,弊社採点サービス「講師速報」にて公開している解答速報をもとに成績を検証していく.(3/15追記:厚生労働省の解答をもとに得点率を再計算しました)
119回医師国家試験の各AIモデルの成績は以下の通りである.
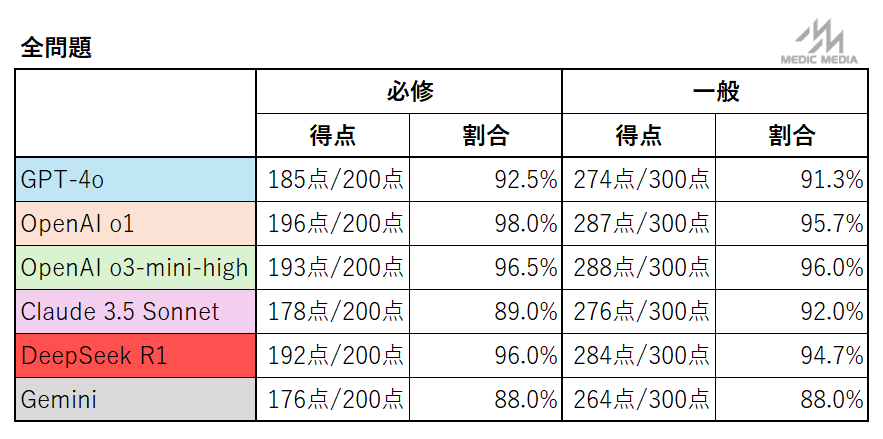
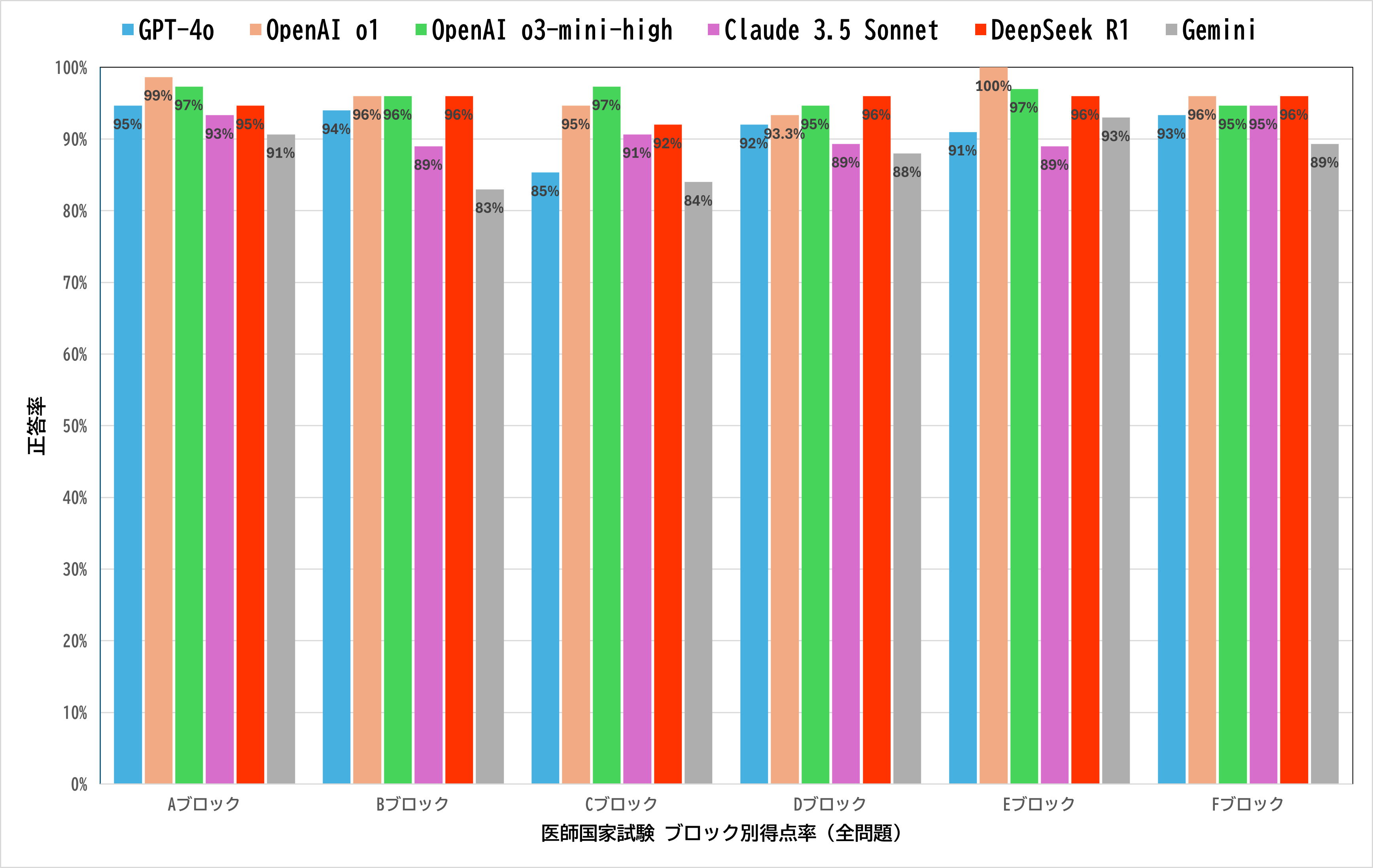
上記結果から分かる通り,必修はOpenAI o1が,一般臨床はOpenAI o3-mini-highが最も成績が良く,これら2つはほぼ同等の結果となった.また,DeepSeek R1もそれに次ぐ結果で,数点差以内に収まっている.
特筆すべきは一般臨床問題の成績であり,o3-miniの96.0%という正答率は仮に国試受験生とすると第3位の成績に相当する(※弊社解答速報サービス「講師速報」に入力した9,642人の成績と比較した).
また,必修問題の得点率98.0%(OpenAI o1)も合格基準の80%を大きく上回っている.受験生の成績と比較すると上位5%程度で,かなりの好成績といえる.
一般臨床問題と必修問題では必修問題のほうが難易度が低い傾向にあるが,AIの得点率はさほど変わらなかった.このことからAIモデルの正誤は問題難易度とは別の要因が関与している可能性が考えられるが,詳細な分析については今後進めていく予定である.
o1,o3-mini-high以外のモデルの成績についても,正答率はやや劣るものの,必修の合格ラインは大きく超えており,一般臨床も受験生と比較し上位である(最も得点率の低かったgemini-2.0-flashの264点も,受験生の上位17%に相当する).このことから,既存のAIモデルはいずれも日本の医師国家試験をクリアできる性能を有しているといえる.
画像問題の有無による検証
先述した通り,医師国家試験には画像を含んだ問題が含まれているが,画像問題を除外した成績結果が以下である.
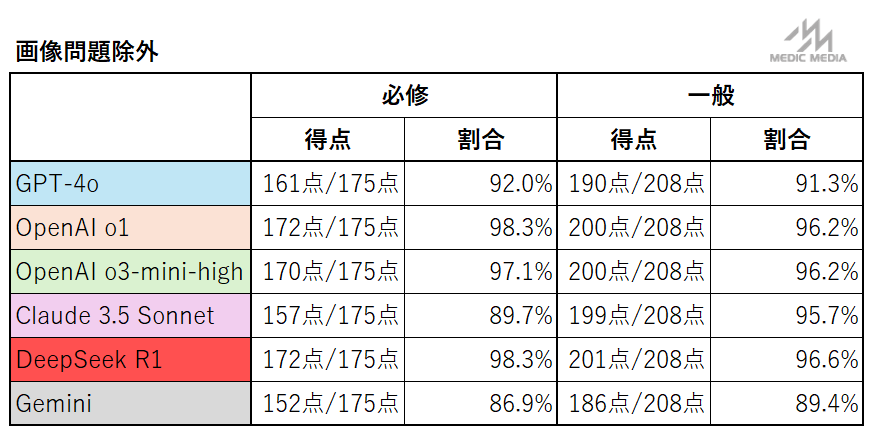
結果としては当初の予想に反し,画像の有無により正答率に大きな差はみられなかった.こちらについては,医師国家試験の性質上,画像以外の情報からも正答を導ける(もしくは選択肢を絞り込める)問題が多いことが理由として考えられる(実際,得点率の高いOpenAI o3-miniやDeepSeek R1はどちらもテキストのみ入力を受け付けるモデルである).
このため,読影など各AIモデルによる画像認識能力の評価は本検証からはできなかった.
AIが不正解となった問題の考察
複数のAIが間違えた問題のうち,いくつかを以下にピックアップした.
全体の傾向としては,日本特有の問題(特に公衆衛生に関連する問題)や優先度をつけさせる問題の正答率が低いといえる.
A-19(受験生正答率:62.5%)

誤答したAI:GPT-4o, o1, o3-mini, Claude, Gemini, Deepseek
正答は「d 自宅待機を指示する.」であるが,検証に用いた全てのAIが「b 保健所に連絡する.」を選択し,間違えた問題である。
本問のポイントは以下である.
1.問題文の“この時点での対応”とは“まず何を行うか”ということであり、患者は結核を疑われることから,感染拡大させない自宅待機を選ばせる.
2.喀痰抗酸菌陽性だけでは結核は確定ではないので(肺MAC症などがあがる),性急に保健所に報告するというのは誤りといえる.
AIは喀痰検査にて抗酸菌陽性ということから,見逃してはならない結核を念頭に置くことができているが初期対応に重点を置かずに解答してしまった.本問を含め,商用の大規模言語モデルは欧米の文書をメインに学習していることも影響しているためか,総じて日本の疫学や公衆衛生問題に弱い傾向が散見された.
B-9(受験生正答率:92.8%)

誤答したAI:o1, Claude, DeepSeek-R1, Gemini
正解は「a ①」である.マルチモーダルモデル(画像も理解できるAIモデル)が実際にどのように画像を処理しているのかは不明だが、よく使われるViT(Vision Transformer)は位置関係の理解が苦手とされているため,誤答した可能性がある.
一方で,驚くべきことに画像処理ができないo3-miniが『……胸骨右縁第2肋間に相当する「1」が正解となる。』と根拠を述べながら正解を選んだ。もはやエスパーの域と言っても過言ではないが,聴診の順番を知っていて胸部における聴診について一般的に設問で割り振られる位置と番号の関係から解答を導いた可能性がある.
B26 (受験生正答率:90.7%)

誤答したAI:GPT-4o, o3-mini, Claude, Gemini
正解は「a 応援を呼ぶ.」であるが,誤答したAIは「d 呼吸の有無を確認する.」を選択した.この問題においても追証されるように,「まず」何をするかを問う問題に対して現行のAIは苦手である傾向にあることがわかった。
一方で,推論力に長けたAIモデルであるo1やDeepSeek-R1は正答である「a 応援を呼ぶ.」を選択した。DeekSeek-R1についてはAIの思考過程である<think>タグの中身を確認すると,「d 呼吸の有無を確認する.」と迷いつつも”まず”という部分について何回も考えることにより見事に「a 応援を呼ぶ.」を答案として導き出した。実に賢いモデルであると思わず感心してしまった。
B-45(受験生正答率:99.9%)

誤答したAI:o1, Claude, Gemini, Deepseek
患者の問診場面における解釈モデルを問う問題で,正解は「e ⑤自分の病気についてどう考えていますか.」である.誤答の理由として,そもそも「解釈モデル」という用語が海外では一般的ではないことが考えられる.他の問題においても,海外で一般的に普及していない概念に関する問いは,間違えやすい傾向があった.
AIの解答作成過程では「d 血圧の薬以外に何か服用されていますか」が最も病歴として重要な情報だと指摘している.一方で正答を導いたo3-miniについては「e 自分の病気についてどう考えていますか」が患者自身の考えを展開できるオープンな質問である一方,他はクローズな質問という判断をした.このことから,o3-miniは正解したものの,「解釈モデル」という用語自体を理解していないことがわかる.
C-6(受験生正答率:57.3%)

誤答したAI:GPT-4o, o1, Gemini
正解は「d 家事動作訓練が含まれる.」であるが,誤答したAIは「c 医師の指示が必要である.」を選んでいた.誤答したAIにおける答案においては,「リハビリテーション=機能訓練」と読み替えて推論されていた.したがって,本問では日本語文を処理する際に,リハビリテーションと機能訓練を混同して解答したAIがあったものと推察される.もしくはより単純に,日本の保険や医療制度に関するデータが少なかったため誤答したということも考え得る.この一方で,o3-miniやDeepseek, Claudeなど本問を誤解なく正答したAIモデルもあり,これらのAIモデル間の挙動の違いには果たして何があるのか疑問を投げかける一問であった.
C-22(受験生正答率:89.5%)
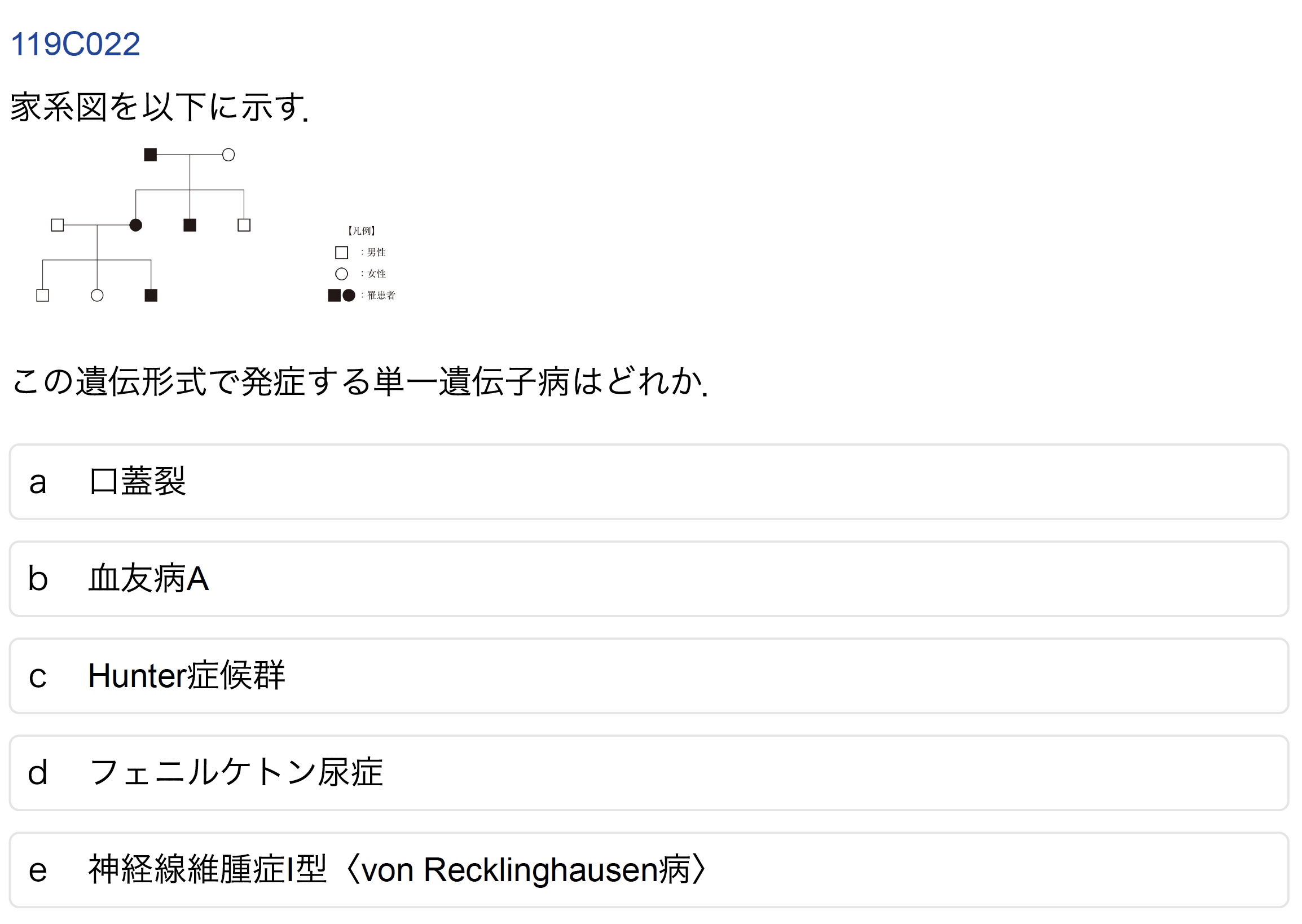
誤答したAI:GPT-4o, o3, Claude, Gemini, Deepseek
家系図の問題である.遺伝形式は常染色体顕性遺伝の様式を示しており「e 神経線維腫症I型」が正答である.o1を除く全てのAIモデルにおいて問題文の家系図を正確に読み解けず,男性のみ罹患していると勘違いしたためX連鎖劣性遺伝と解釈した.
家系図の画像を理解しつつ,遺伝様式に慎重に検討したo1のみ正解を導いた.
C-47(受験生正答率:49.2%)

誤答したAI:GPT-4o, Gemini
正答は「d 二酸化炭素中毒」である.受験生の間でも物議を醸した問題であり,過去に実際に起きた事故を題材に作問されたものと思われる.
多くのAIが誤答しており,日本の葬祭・埋葬様式である通夜や火葬,棺といった慣習や制度,また通夜から火葬にかけてドライアイスで故人を保管するという知識から事故原因を推測することはAIでも流石に難しそうであった(多くの受験生も混乱したであろう).
o1およびo3-miniでは正解していたものの,o3-miniの解答理由は「呼気による二酸化炭素中毒が原因である」という若干異なる解釈をしていた.しかし,o1では解答根拠として遺体の冷却にドライアイスが使われることを指摘しており,日本の葬儀に関する背景知識を応用することができている.
C-52(受験生正答率:48.6%)

誤答したAI:GPT-4o, o1, o3-mini, Claude, Gemini, DeepSeek-R1
検証に用いた全AIが間違えた問題.本問で患児が登校できるようになるのは「d 7日(木)」である.
本邦においてインフルエンザ感染症の出席停止期間が「発症した後5日を経過し,かつ解熱後2日(48時間)を経過するまで」と法令で定められていることは全モデルが知っていたが,法令の運用における日付の数え方までは把握していなかった.発症した日(発熱が始まった日)は含まず0日目とし,翌日からを第1日目として数えることを知っていれば答えられただろう.
なおo3-mini-highについて,APIでは画像の入力ができないが,サイト上では画像の入力が可能である(2025年2月28日現在).そのためこの問題について再試行したところ,かなり正確な推論の上で正答「d 7日(木)」を答案として選択した.
D-19(受験生正答率:61.6%)
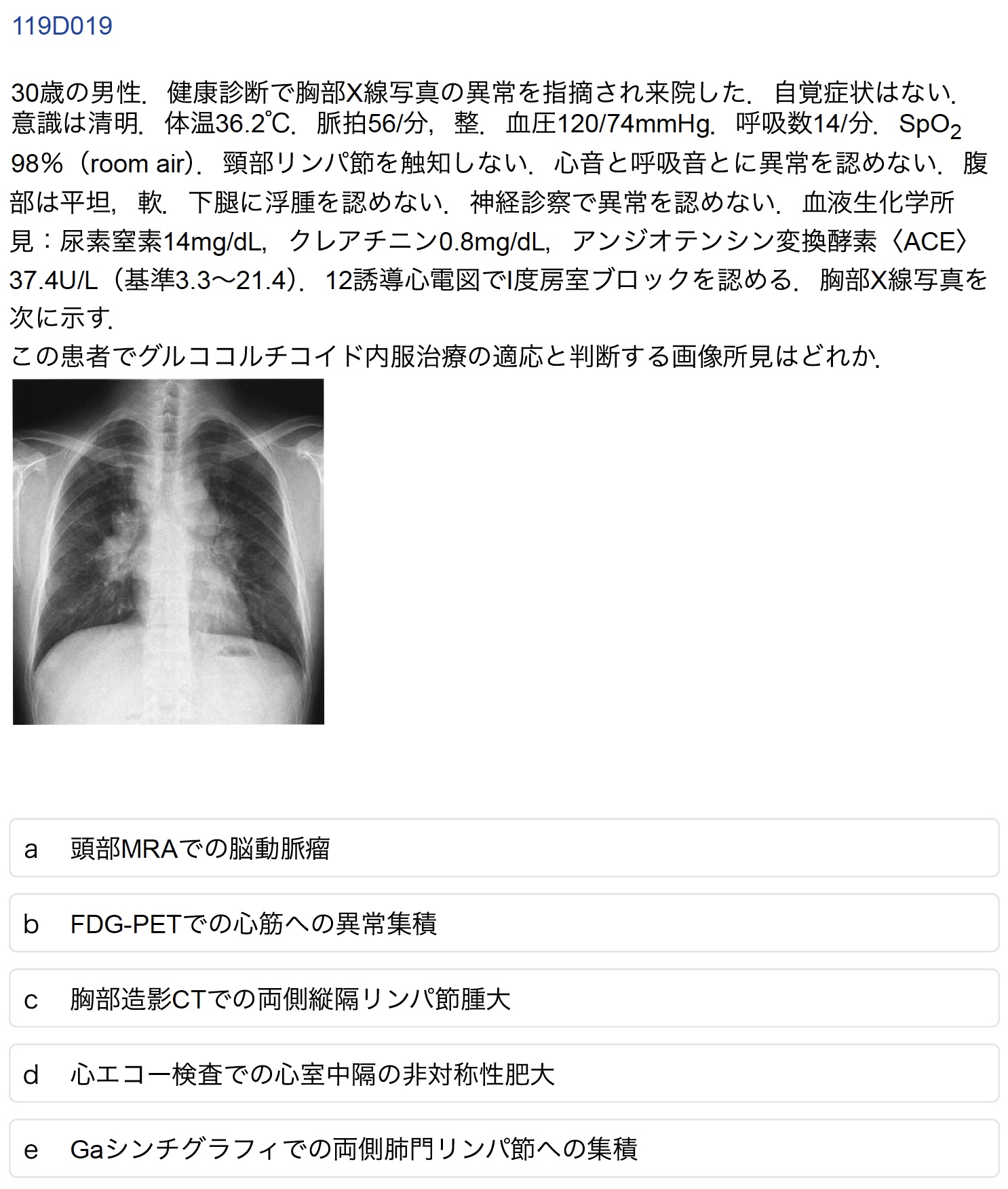
誤答したAI:Claude, Gemini
正答は「b FDG-PETでの心筋への異常集積」である.正答したAIは心サルコイドーシスにおける心臓病変の重要性・優先性を認識し,FDG-PETでの心筋集積を治療適応の根拠とした.一方で誤答したAIはサルコイドーシスの典型的な画像所見である両側肺門リンパ節腫大を重視し,胸部CTでの所見(選択肢はc)を治療適応と判断した.臨床的な重症度を考慮した場合,心臓病変の方が治療介入の緊急性が高いという医学的知識の深さにAI間で差が出たと考えられる.
D-21(受験生正答率:59.4%)
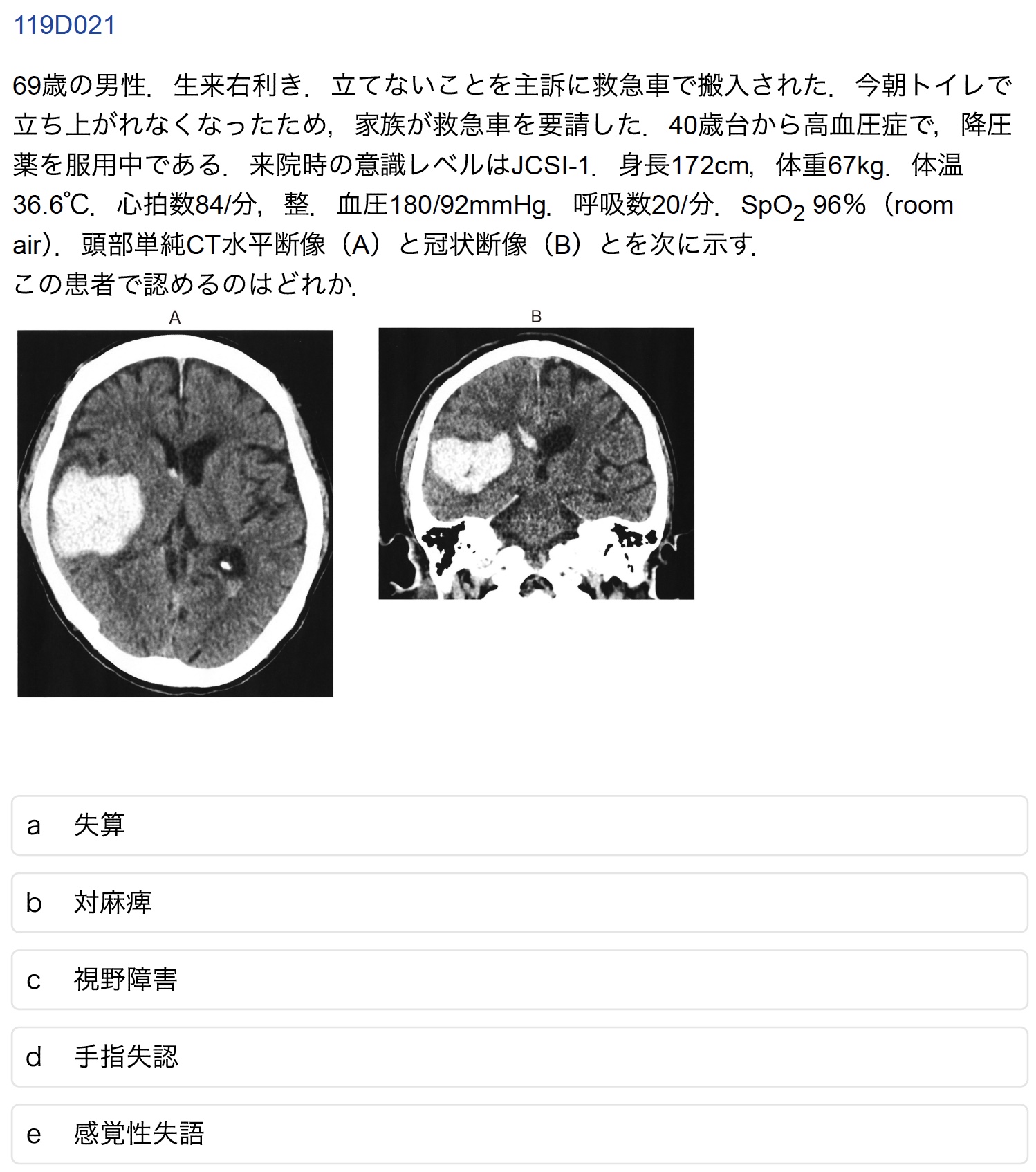
誤答したAI:o1, o3-mini, Claude
正答は「c 視野障害」である.誤答したAIにおいては提示されたCT画像における障害部位(側頭葉における広範な出血)とそれに対する神経学的部位の対応付けに誤りがみられた.本文において特筆すべきは,推論モデルであるo1が誤答であったにも関わらずGPT-4oが正答できていたことである.事実上の上位モデルであるo1が間違い,下位モデルであるGPT-4oが正答するのは珍しい.
D-54(受験生正答率:79.7%)
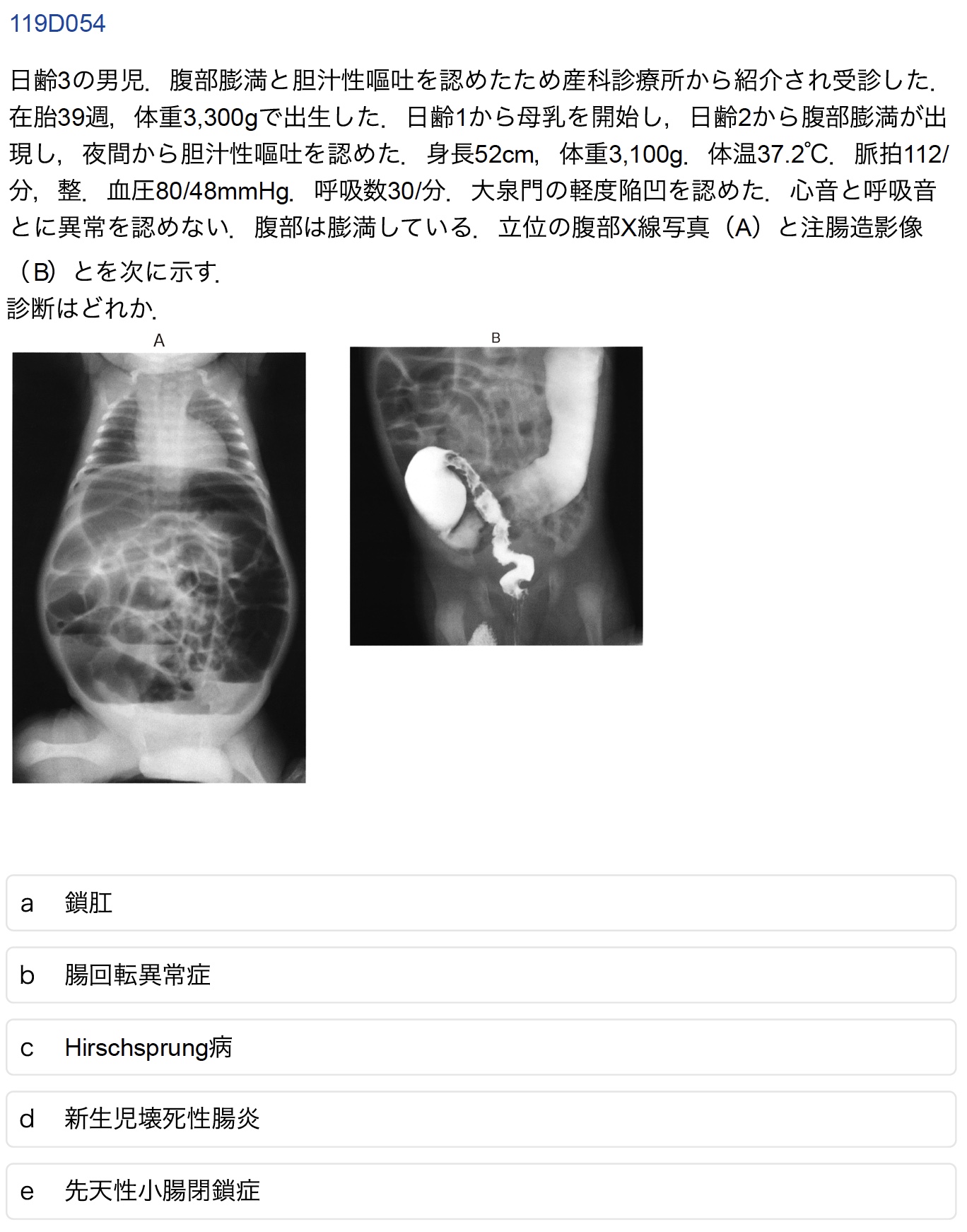
誤答したAI:GPT-4o, o1, o3-mini, Claude, Gemini, Deepseek
正答は「c Hirschprung病」である.今日のAIモデルには比較的稀な疾患であるこのHirschprung病の知識がない事がしばしばあり,筆者はAIモデルに医療系知識があるかのベンチマークにすることもある.
E12(受験生正答率:91.4%)
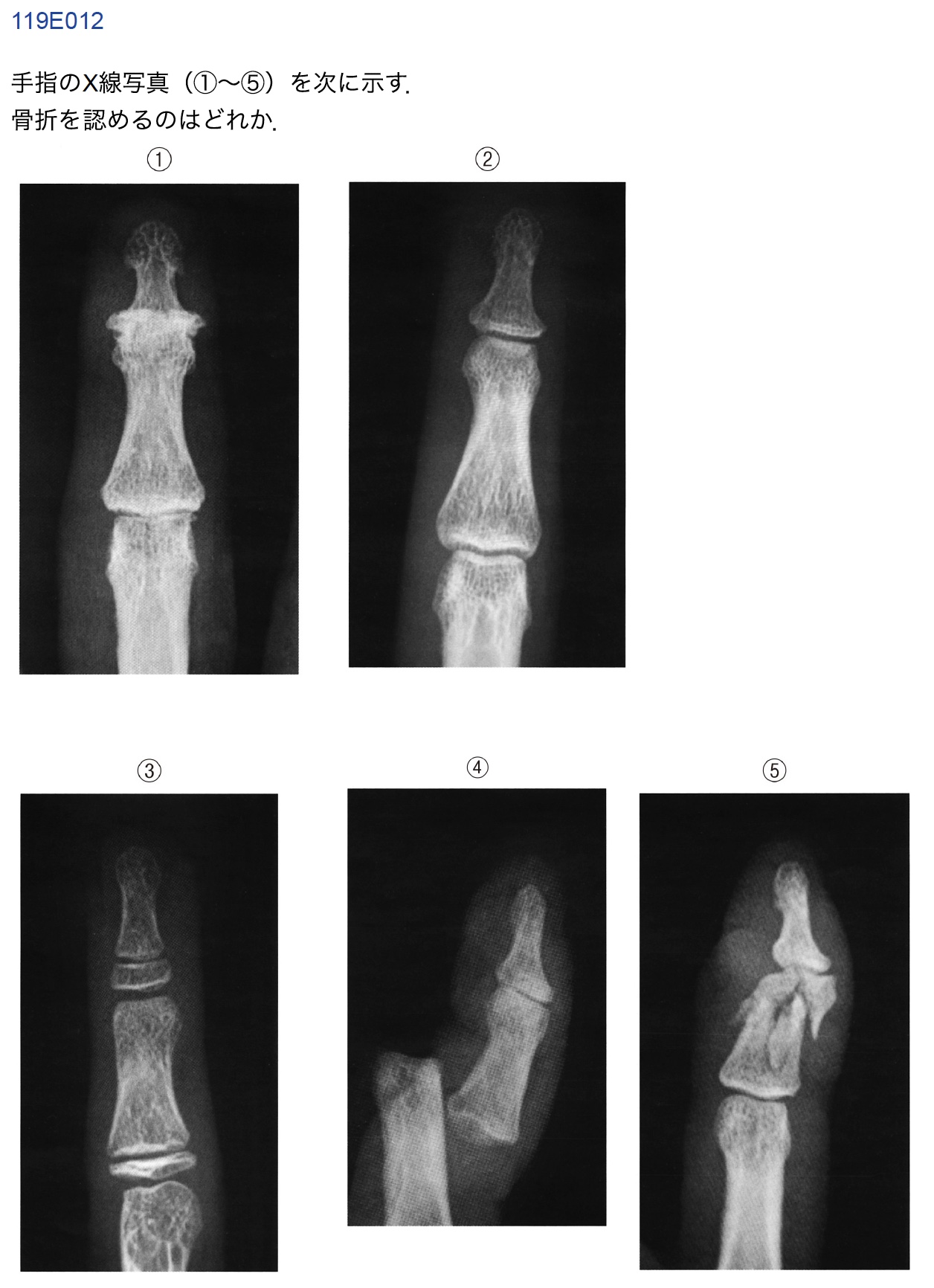
誤答したAI:GPT-4o, o3-mini, Claude, Deepseek
受験生の間でも少し話題になっていた問題である.正答は「e ⑤」.皮膚から突き出てる脱臼と粉砕骨折に関する一題である.誤答したAIは「d ④」を選択した.
正答のAIは「⑤番の像は骨片が多数に分かれており,明らかな骨折」と解答しており,粉砕骨折を明確に読影した.本問を正解したGemini2.0-flashだが,総合成績では他モデルと比較すると振るわなかったものの,一部の医療画像はかなり的確に理解できていた.
E24(受験生正答率:99.7%)

誤答したAI:o3-mini, Claude, Deepseek
正答は「e 5」である.処方箋を字面通りに読解することができれば容易に正答にたどり着けるものの,画像を読むことのできないモデルには無理があったか.
E-39(受験生正答率:92.2%)
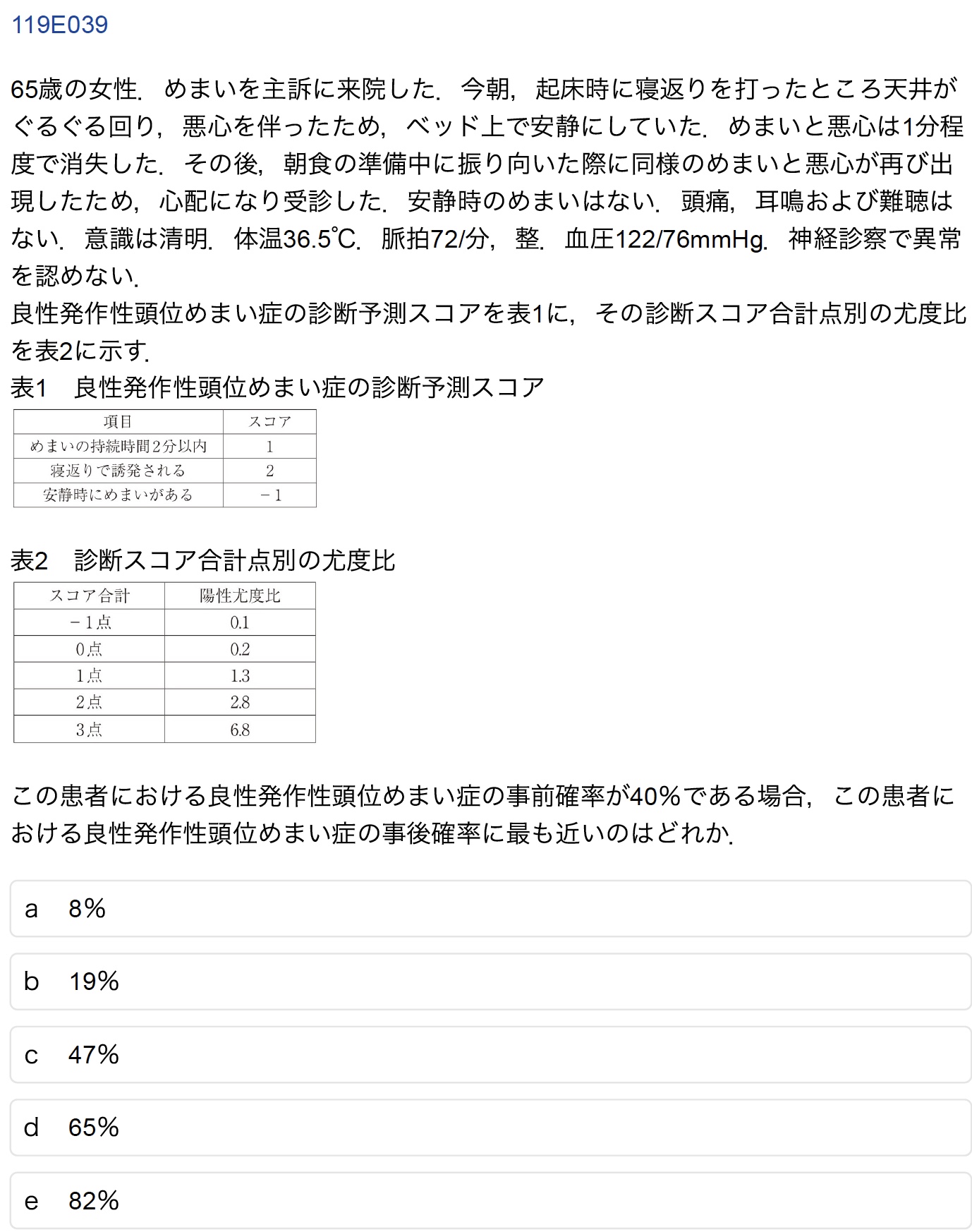
誤答したAI:GPT-4o, Claude, Gemini
正答は「e 82%」.オッズを用いて検査前確率から検査後確率を求める問題である.誤答したAIはいずれも非推論モデルであり,簡単な算数の問題でも間違えることがある.そのため,本問のような算術問題に解答するのは難しかったようである.
F-31(受験生正答率:64.3%)

誤答したAI:GPT-4o, o3-mini, Gemini
正答は「a 一般病床」と「d 療養病床」であるが,誤答しているAIでは「d 療養病床」のかわりに「c 精神病床」を選んでしまい不正解に陥っている.やはり日本の医療制度について有している知識が弱いようである.この一方で,o1やDeepseekは解けており,このような知識もきちんと学習していることが伺える.
F-67(受験生正答率:89.2%)

誤答したAI:GPT-4o, o1, o3-mini, Claude, Gemini, Deepseek
正答は「c ビタミンB1」と「e 甲状腺刺激ホルモン〈TSH〉」であるが,まさかのAIは全滅という結果であった.
すべてのAIがを「a 葉酸」と「e 甲状腺刺激ホルモン〈TSH〉」選択.Treatable dementia(治療可能な認知症)に関する出題であり,医師国家試験としては典型的すぎる問題であるので,受験生の正答率は高かったであろう.これを間違えたAIは痛恨である.日本より海外ではサプリメントの文化が強く,葉酸=記憶力のような安直な結びつきが強いことも原因に挙げられるかもしれない.海外ではサプリも医療も一緒くたな上に,インターネット上にはサプリの情報のほうが溢れているため,AIが騙された可能性が高い.典型的なハルシネーションといえる.


